Implementing a Language in C# - Part 4: Parser Setup

This post is part of a series entitled Implementing a Language in C#. Click here to view the first post which covers some of the preliminary information on creating a language. Click here to view the last post in the series, which covers some of the fundamentals of building a parser. You can also view all of the posts in the series by clicking here.
As I explained in the previous post, the purpose of the parser is to generate an Abstract Syntax Tree from the given tokens emitted by the lexer. In this post, I will explain some of the intricacies of the Abstract Syntax Tree as well as how to implement some of the basics of the parser.
Abstract Syntax Tree
The Abstract Syntax Tree is the core component of the interpreter we will be building. After parsing, the computer can directly execute operations using the generated tree. The AST, like the name suggests, is a tree which represents the structure of a program. An example of "Hello, World" in GlassScript could look as follows:
Code: console.print("Hello, World");
AST:
MethodCallExpression {
Arguments = List<Expression> {
ConstantExpression {
String Literal: "Hello, World"
}
},
Reference = ReferenceExpression {
IdentifierExpression {
"console"
},
IdentifierExpression {
"print"
}
}
}
The root of the Abstract Syntax Tree for GlassScript is SyntaxNode. All types of AST derive from this abstract class. From SyntaxNode, there are four paths: Declaration, Statement, Expression, and SourceDocument. The Declaration node is the supertype of all declaration nodes: classes, methods, fields, variables, etc. The Statement node is the supertype of all statements: if, while, for, etc. Expression is the supertype of all expressions: method calls, binary operations, etc. The SourceDocument contains top-level classes, methods, and statements.
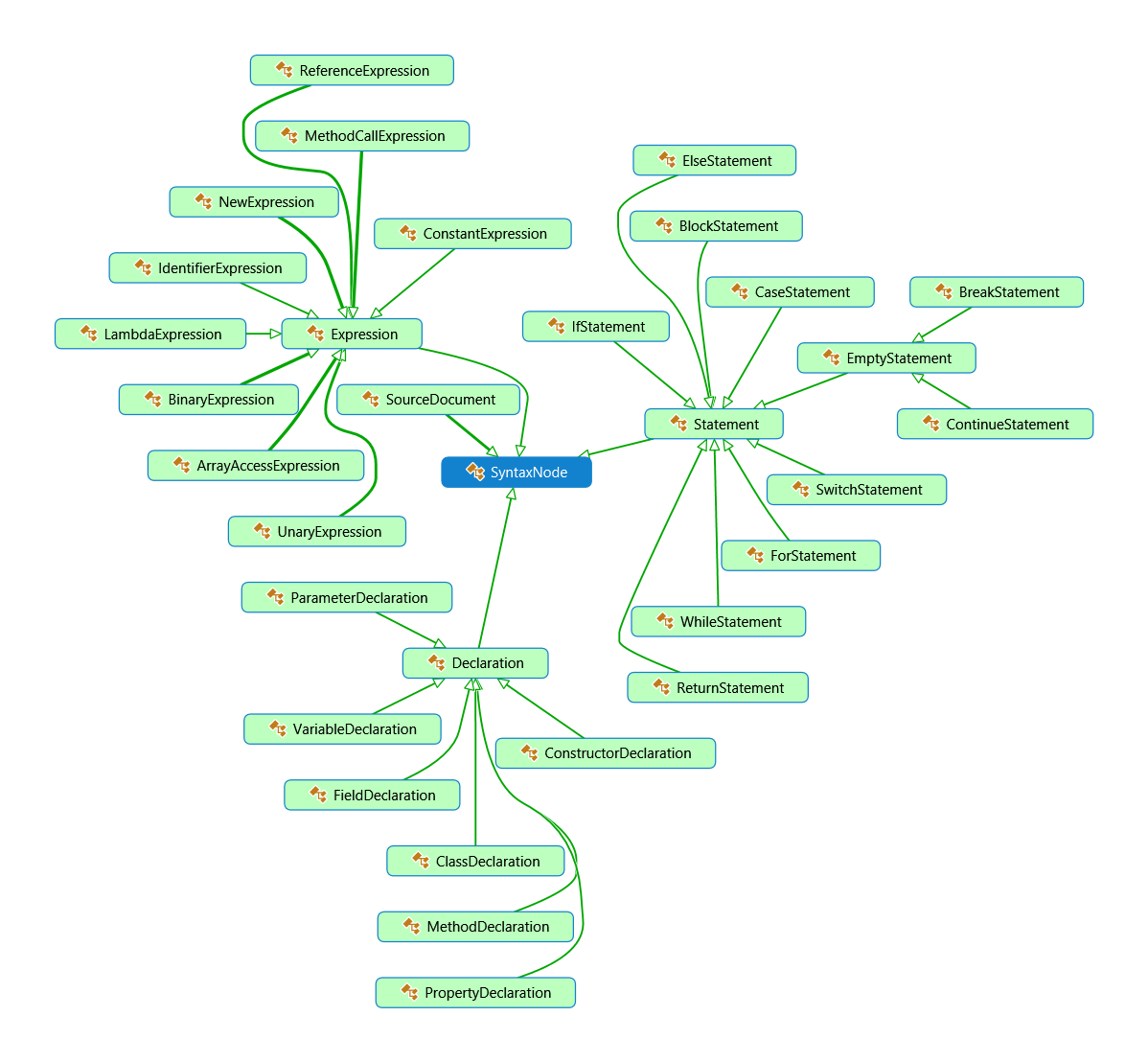
Each of these different nodes instruct the interpreter to do something. Declarations are almost never directly evaluated, only their information cached. Statements will almost always return a Completion, which is a special type that contains information regarding how the statement exited and how to continue (this will be further covered in a future post). Expressions are always actions of some kind which return a value (e.g. 1 + 1 returns 2); without them, there would be no language.
Before We Start
There are several ways to implement the parser. One option is to include the methods for processing tokens in a Parser class and move parsing functionality into static methods contained in the AST nodes; another method would be writing the entire parser in one massive file; or we could implement the parser in a partial class, which allows us to keep all of the logic internalized without the overhead of a 1,500 line file. Given the options, I have opted to implement the third in GlassScript.
Before we begin to implement the parser, I suggest writing some utilities that will consume tokens, merge SourceSpans, and generate errors. These helper methods saved hundreds of lines of code for GlassScript and simplified the code soup of expression parsing.
Consuming Tokens:
private Token Take()
{
var token = _current;
Advance();
return token;
}
private Token Take(TokenKind kind)
{
if (_current != kind)
{
throw UnexpectedToken(kind);
}
return Take();
}
private Token Take(string contextualKeyword)
{
if (_current != TokenKind.Identifier && _current != contextualKeyword)
{
throw UnexpectedToken(contextualKeyword);
}
return Take();
}
private Token TakeKeyword(string keyword)
{
if (_current != TokenKind.Keyword && _current != keyword)
{
throw UnexpectedToken(keyword);
}
return Take();
}
Generating Errors:
private void AddError(Severity severity, string message, SourceSpan? span = null)
{
_errorSink.AddError(message, _sourceCode, severity,
span ?? CreateSpan(_parseStart, _current.Span.End));
}
private SyntaxException SyntaxError(Severity severity, string message, SourceSpan? span = null)
{
AddError(severity, message, span);
return new SyntaxException(message);
}
private SyntaxException UnexpectedToken(TokenKind expected)
{
return UnexpectedToken(expected.ToString());
}
private SyntaxException UnexpectedToken(string expected)
{
string message = $"Unexpected '{_current.Value}'. Expected '{expected}'";
Advance();
return SyntaxError(Severity.Error, message, _current.Span);
}
Recovering From Errors
Error recovery is often a difficult task. This is especially true in recursive descent parsers like this one. In the context of this parser, an error is defined as when the given program attempts to transition to an invalid state. For example, prop<int> test => } would produce an invalid state. This is because when the parser reaches =>, it expects either a new scope or an expression. Instead, the parser gets a right bracket. This causes the parser to enter an invalid state.
Error recovery is the act of safely transitioning out of an invalid state. As I said, in recursive descent parsers, this process is difficult. You have three basic options: implement helpers to keep track of the last good state and a system of returning to it, litter your code with try/catch clauses, or blindly skip to the next token and try again. These three options are mixable, however, and that is what I attempted to implement.
The first step was to implement two helper methods that keep track of the last good state. These are the MakeBlock and MakeStatement methods. These two statements accept an Action which contains the parse logic for a given error-prone region (expressions, block transitions, etc).
MakeBlock and MakeStatement also contain a try/catch/finally clause which allows control to be returned to the calling rule. This allows the parser to return to a good state without SyntaxExceptions boiling back to the surface.
The final feature of these two methods is token skipping. Each call to MakeStatement or MakeBlock contains information on how to transition back to a valid state after an error. This allows control to be returned to the rule with the last valid state, allowing it to continue to parse as if nothing had happened.
Generating Meaningful Errors
Finally, it is important to know how to generate a meaningful error. While you can rely on errors generated from Take() and its overloads, they tend to generate errors like Unexpected '{'. Expected 'LessThan' which has no inherent meaning to the programmer. In reality, this was an error generated from parsing a type annotation. The fix for this was a simple if statement at the begining of the rule:
if (_current != TokenKind.LessThan)
{
throw UnexpectedToken("Type Annotation");
}
Instead of Expected 'LessThan', we now get a more helpful Expected 'Type Annotation'. Much more helpful!
Conclusion
That brings us to the end of this post. Next time, we'll cover some actual parsing. As usual, you can view the full source code for the current post by going to the project's GitHub.