Implementing a Language in C# - Part 2: The Lexer
The lexer, also known as a Tokenizer or Scanner, is the first step of the compilation process. This post demonstrates the most important considerations to take into account when building a lexer.

This post is part of a series entitled Implementing a Language in C#. Click here to view the first post which covers some of the preliminary information on creating a language. You can also view all of the posts in the series by clicking here.
The lexer, also known as a Tokenizer or Scanner, is the first step of the compilation process. The job of the lexer is to take the programmer's input and split it up into individual tokens -- things like keywords, variable names, punctuation, and operators -- according to the rules of the language in question. These tokens are the atoms of our programs, the smallest individual unit of code.
The lexer takes my var name = console.read(); and turns it into Keyword (var) Space Identifier (name) Space Assignment Space Identifier (console) Dot Identifier (read) LeftParenthesis RightParenthesis Semicolon. The latter, with little modification, is what a parser will accept and transform into an Abstract Syntax Tree.
Because of its simplicity, the lexer is often the component which raises the fewest syntax errors. However, just because I said fewest doesn't mean that the lexer doesn't throw any errors. There are inputs which are incorrectly formatted, such as .e-10 as a float value or 1variable in many languages. This is why the rules of the lexer are important and why we need a good way to raise errors throughout our compilation process.
Enter the Error Sink
The Error Sink is a component of the compilation process that follows the code throughout its transformation. Its purpose is to provide a standard mechanism for reporting errors in the user's code. Building a workable Error Sink is not difficult; it's just a collection of error messages. But, its contribution to the debugging process is invaluable (just try writing code without any feedback on why it won't compile).
Consider what information makes a helpful error. Things like line number, column, and specifically what is wrong. So, that's what we will include in the ErrorEntry class.
public sealed class ErrorEntry
{
public string Line { get; }
public string Message { get; }
public Severity Severity { get; }
public SourceSpan Span { get; }
}
In my implementation, I found it helpful to include the line contents for when outputting the error to the console. This small tidbit allowed the ability to emulate the squiggles one might find in an IDE.
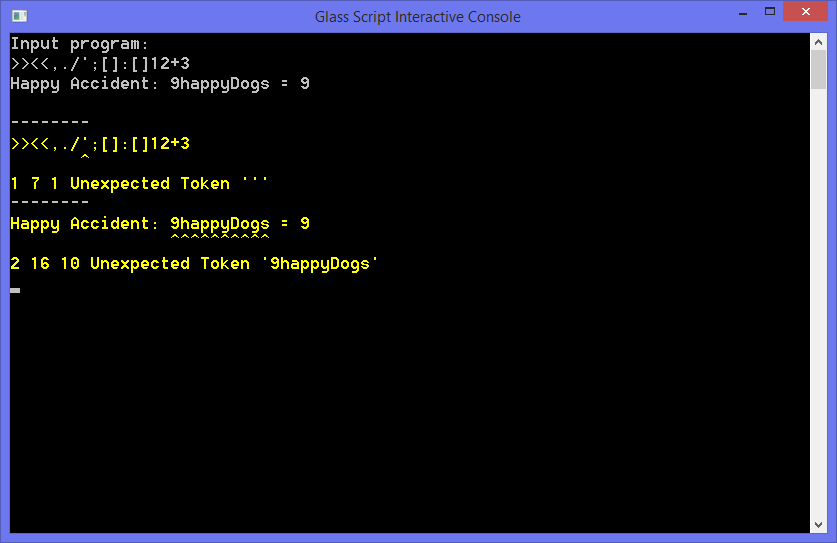
Because not all errors are bad, a severity is included to indicate the recoverability of the error. A Message is reserved for things like stylistic hints, a Warning for unused variables, an Error for invalid names, and a Fatal error is reserved only for thing which force the compilation or execution process to halt.
public enum Severity
{
None,
Message,
Warning,
Error,
Fatal
}
Now, with the requirements for our Error Sink out of the way, we can implement a quick solution:
public class ErrorSink
{
private List<ErrorEntry> _errors;
public IEnumerable<ErrorEntry> Errors => _errors.AsReadOnly();
public ErrorSink()
{
_errors = new List<ErrorEntry>();
}
public void AddError(string message, string line, Severity severity, SourceSpan span)
{
_errors.Add(new ErrorEntry(message, line, severity, span));
}
public void Clear()
{
_errors.Clear();
}
}
Lexical Analysis
With our Error Sink complete enough, we can begin on the lexer. If you haven't already, think about what you want your lexical rules to be. What operators will you want? How will code comments be formatted? These are the questions you want to be focusing on before writing a lexer.
A lexer is a type of program that is known as a Deterministic finite automaton -- that is, it takes a finite string of characters and outputs a deterministic result in the same way that 2 + 3 always outputs 5. For this reason we must ensure that for a given input, the output is always the same. The best way to implement this is to use plain-old branching logic.
Expressing Grammar
When you think about it, the lexical rules of most programming languages could be expressed with a series of Regular Expressions, each rule corresponding to one RegEx. The problem is, they are all too often unreadable. RegExs are great, but in this case, they're just not the right tool for the job.
That is why Extended Backus–Naur Form is one of the most useful tools for describing the rules of a language. It combines the power and precision of Regular Expressions without most of the headache.
In EBNF, we can describe the rules of an identifier as the following:
letter = "A" | "B" | "C" | "E" | "F"
| "G" | "H" | "I" | "J" | "K"
| "L" | "M" | "O" | "P" | "Q"
| "R" | "S" | "T" | "U" | "V"
| "W" | "X" | "Y" | "Z ;
digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ;
letter or digit = letter | digit ;
identifier = ( "_" | letter ), { letter or digit } ;
This makes the process of thinking through the rules of our language much easier. An integer, for example, could be expressed as integer = digit, {digit} ;.
Floating point numbers, however, are harder. This is because both .1 and 9.315e-27f are both valid inputs. Writing an unambiguous rule for cases like this are difficult, let alone implementing one. My best attempt so far has been
ten to the n = "e", [ "+" | "-" ], integer ;
point float = ".", integer ;
simple float = integer, point float ;
science float = [ digit ], point float, ten to the n ;
whole number sf = digit, ten to the n ;
float = ( ( point float | simple float | science float | whole number sf ), [ "f" ] ) | ( integer, "f" ) ;
The question now becomes how we can implement our new rules as code. A general rule of thumb is to implement one rule per method. For example:
private Token ScanInteger()
{
while (IsDigit())
{
Consume();
}
if (_ch == 'f' || _ch == '.' || _ch == 'e')
{
return ScanFloat();
}
if (!IsWhiteSpace() && !IsPunctuation() && !IsEOF())
{
return ScanWord();
}
return CreateToken(TokenKind.IntegerLiteral);
}
In this example, we can see the implementation of the integer rule.
In the lexer, I implemented several helper methods to cut down on the clutter of this already complex system. The Consume() method adds the current character to the current token's StringBuilder and advances the index pointer. The ScanWord() method follows the current "word" to the next space, punctuation mark, or the end of the file and then outputs an error. The CreateToken(TokenKind) method takes the currently stored token information, returns it as a token, then begins the next token at the current index.
Because the float rule can begin with an integer, a check is included to see if the current token is a float.
The ScanFloat() method is what I eventually settled on after several hours of thinking about how to implement such a difficult rule. My solution that ended up satisfying the implementation requirements was the following:
private Token ScanFloat()
{
if (_ch == 'f')
{
Advance();
if ((!IsWhiteSpace() && !IsPunctuation() && !IsEOF()) || _ch == '.')
{
return ScanWord(message: "Remove 'f' in floating point number.");
}
return CreateToken(TokenKind.FloatLiteral);
}
int preDotLength = _index - _tokenStart.Index;
if (_ch == '.')
{
Consume();
}
while (IsDigit())
{
Consume();
}
if (_last == '.')
{
// .e10 is invalid.
return ScanWord(message: "Must contain digits after '.'");
}
if (_ch == 'e')
{
Consume();
if (preDotLength > 1)
{
return ScanWord(message: "Coefficient must be less than 10.");
}
if (_ch == '+' || _ch == '-')
{
Consume();
}
while (IsDigit())
{
Consume();
}
}
if (_ch == 'f')
{
Consume();
}
if (!IsWhiteSpace() && !IsPunctuation() && !IsEOF())
{
if (IsLetter())
{
return ScanWord(message: "'{0}' is an invalid float value");
}
return ScanWord();
}
return CreateToken(TokenKind.FloatLiteral);
}
It's not any work of art, but it's readable and gets the job done.
Identifiers and keywords are the final point I wanted to touch on in this post. The two follow the same general rules for lexing. A quick and simple method for checking if a token matches a keyword is simply to check that fact just before returning the resulting token. It is for this reason that my lexer does not contain a ScanKeyword method.
private static readonly string[] _Keywords = { "class", "func", "new", "if", "else", "switch", "case", "default", "do", "while", "for", "var", "null" };
private bool IsKeyword()
{
return _Keywords.Contains(_builder.ToString());
}
private Token ScanIdentifier()
{
while (IsIdentifier())
{
Consume();
}
if (!IsWhiteSpace() && !IsPunctuation() && !IsEOF())
{
return ScanWord();
}
if (IsKeyword())
{
return CreateToken(TokenKind.Keyword);
}
return CreateToken(TokenKind.Identifier);
}
Conclusion
That brings us to the end of this post. Next time, I will be giving an overview on the parser. As usual, the full source code for this post is included on GitHub.